
สวัสดีครับ ทุกวันนี้ ก็มีหลางองค์กร ที่ให้ความสำคัญกับการนำ AI มาใช้งาน และสิ่งที่สำคัญอีกอย่างนึงของการพัฒนา AI นั่นก็คือ ฐานข้อมูล วันนี้เราจะมาคุยเรื่อง Vector Database หรือ ฐานข้อมูลชนิดหนึ่งที่ถูกออกแบบมาเพื่อจัดเก็บและจัดการข้อมูลในรูปแบบของเวกเตอร์ (Vector) ซึ่งเป็นข้อมูลที่ถูกแปลงให้อยู่ในรูปของเวกเตอร์โดยใช้โมเดล Machine Learning หรือเทคนิคการประมวลผลภาษาธรรมชาติ (NLP) เพื่อให้สามารถค้นหาข้อมูลได้อย่างรวดเร็วและมีประสิทธิภาพสูง โดยเฉพาะในกรณีที่ต้องการค้นหาข้อมูลที่มีความคล้ายคลึงกัน ก็จะมีหลายสำนัก ในเน็ต นะครับลองเปิดอ่านหรือ ลองเปิด ChatGPT ก็ได้ คิดว่าน่าจะคล้าย ๆกัน แต่ผมจะนำเสนอจาก สิ่งที่ได้ทำมาแล้วเอามาเล่าสู่กันฟังครับ
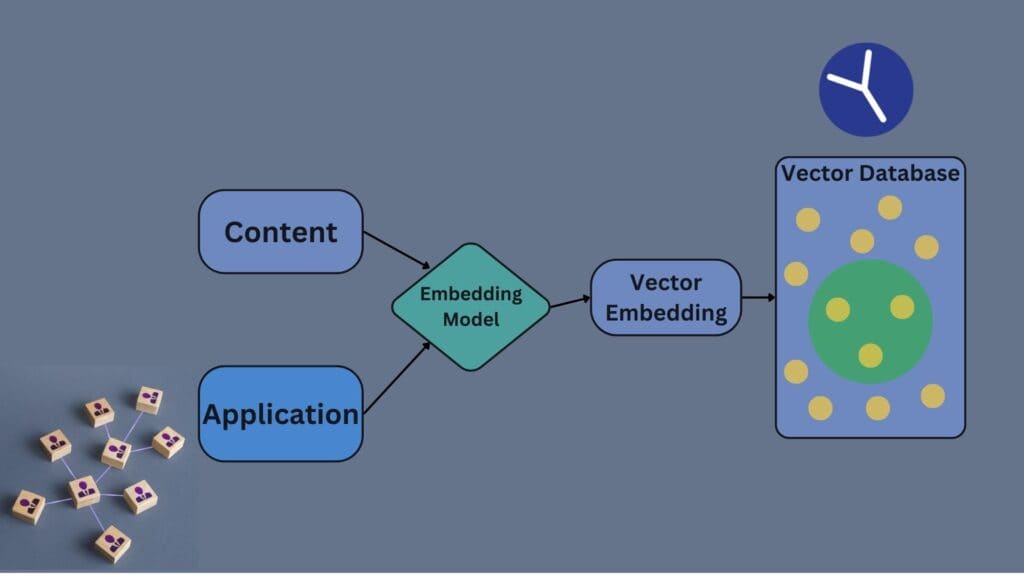
โครงสร้างของข้อมูลแบบเวกเตอร์
ในระบบ Vector Database ข้อมูลแต่ละรายการจะถูกแปลงเป็นเวกเตอร์ (มักเป็นตัวเลขทศนิยมในหลายมิติ) เช่น รูปภาพอาจถูกแปลงเป็นเวกเตอร์ที่มี 128 มิติหรือมากกว่า และข้อความอาจถูกแปลงเป็นเวกเตอร์ 300 มิติขึ้นไป ก็คือ มันจะมี มิติ ของมันแล้วเราก็กำหนด มิติเหล่านั้นให้มัน จะละเอียดกว่าตอนเราเรียน คณิตศาสตร์หรือ ฟิสิกส์ ตอนมัธยม ก็คือมีการนิยามว่า จะมี ขนาดและทิศทาง .. ตัวเลขเหล่านี้จะช่วยแสดงถึงคุณสมบัติของข้อมูล เช่น สี รูปร่าง หรือบริบทของข้อความ ทำให้ระบบสามารถนำเวกเตอร์เหล่านี้ไปเปรียบเทียบกับเวกเตอร์อื่น ๆ ได้

การนำฐานข้อมูลแบบเวกเตอร์ไปประยุกต์ใช้งาน
Vector Database เหมาะสมกับงานที่ต้องการการค้นหาในลักษณะ Approximate Nearest Neighbor (ANN) ที่ต้องการค้นหาข้อมูลที่มีความคล้ายคลึงกันในระดับสูง ตัวอย่างเช่น:
- การค้นหาภาพที่คล้ายกัน: เช่น การค้นหาภาพในแอปพลิเคชัน Social Media หรือ e-commerce เพื่อแสดงผลิตภัณฑ์ที่ใกล้เคียงกัน
- การแนะนำเนื้อหา: เช่น การแนะนำหนังสือ บทความ หรือเพลงที่มีความคล้ายคลึงกับสิ่งที่ผู้ใช้งานเคยเลือก
- การจับคู่เอกสาร: การใช้ในระบบค้นหาเอกสารหรือบทความที่เกี่ยวข้องกันในเชิงเนื้อหา ตัวอย่าง มิติเบื้องต้น ในการทำการจับคู่เอกสาร
-Topic Embeddings (ฝังหัวข้อ)
-ความรู้สึก (Sentiment)
-สไตล์การเขียน (Writing Style)
-คำสำคัญเฉพาะ (Specific Keywords)
-บริบททางภูมิศาสตร์และวัฒนธรรม (Geographical and Cultural Context)
-เวลาที่เกี่ยวข้อง (Temporal Information)
ตัวอย่าง use case หัวข้อ การศึกษาด้าน AI ในปี 2024
[Topic_AI: 0.85, Topic_Education: 0.7, Sentiment_Positive: 0.3, Style_Formal: 0.6,
Keyword_Analysis: 0.9, Geography_Global: 0.5, Year_2024: 1.0]
-Topic_AI และ Topic_Education เป็นมิติที่แสดงหัวข้อของเอกสาร
-Sentiment_Positive แสดงความเป็นบวกของเนื้อหา
-Style_Formal ระบุสไตล์การเขียนว่าเป็นทางการ
-Keyword_Analysis มีค่าใกล้ 1.0 เนื่องจากเอกสารนี้มีการพูดถึงการวิเคราะห์
-Geography_Global ระบุบริบทที่เป็นระดับสากล
-Year_2024 แสดงถึงความเกี่ยวข้องกับปี ค.ศ. 2024
- บริการสตรีมเพลงและมัลติมีเดีย: สามารถสร้างการแสดงเวกเตอร์ของเพลงทุกเพลงในบริการสตรีมเพลงอย่าง Spotify ได้โดยใช้แอตทริบิวต์ เช่น ประเภทเพลง จังหวะ ทำนอง และเครื่องดนตรี นี่เป็นอีกกรณีการใช้งานการค้นหาความคล้ายคลึงที่มีประสิทธิภาพ
- รถยนต์ไร้คนขับ: ฐานข้อมูลเวกเตอร์มีความจำเป็นต่อการประมวลผลข้อมูลเซ็นเซอร์ในรถยนต์ไร้คนขับ เพื่อให้รถยนต์สามารถเข้าใจและนำทางสภาพแวดล้อมได้ ฐานข้อมูลดังกล่าวแปลงอินพุตเป็นข้อมูลเวกเตอร์จากแหล่งข้อมูลของไลดาร์ เรดาร์ และกล้อง นักวิเคราะห์สามารถใช้ข้อมูลดังกล่าวเพื่อระบุแนวโน้มสำคัญต่างๆ เช่น สิ่งกีดขวาง สัญญาณไฟจราจร และคนเดินถนน
ปัจจุบัน ก็มีฐานข้อมูลหลายยี่ห้อ ที่เพิ่มเติมในส่วน function ของ เวกเตอร์ ไม่ว่าจะเป็น Redis, MongoDB Atlas, LlamaIndex, Oracle, Qdrant หรือ อื่นๆ (สามารถดูเพิ่มเติมใน วิกิได้) แต่ Developer ควรคำนึงถึง ประสิทธิภาพการใช้งาน และ performance เพราะลักษณะงานของการใช้ ฐานข้อมูลแบบเวกเตอร์ จะมีการใช้ ทรัพยากรค่อนข้างเยอะเมื่อเทียบกับ ฐานข้อมูลธรรมดา เช่นเดียวกัน บน cloud หรือ softwas as a service(SAAS) เมื่อใช้ทรัพยากรเยอะ ค่าใช้จ่ายก็จะเยอะขึ้น







